[가상 면접 사례로 배우는 대규모 시스템 설계 기초] 6장 : 키-값 저장소 설계
키-값 저장소(key-value store)는 비 관계형 데이터베이스이다. 이 저장소에 저장되는 값은 고유 식별자를 키로 가져야한다.
키-값 쌍에서 키는 유일해야 하며 키에 매달린 값은 키를 통해서만 접근할 수 있다.
- 아마존 다이나모
- memcached
- Redis
CAP 정리
분산 시스템을 설계할 때는 CAP 정리(Consistency, Availability, Partition Tolerance theorem)를 이해하고 있어야 한다.
CAP 정리는 데이터 일관성(Consistency), 가용성(Availability), 파티션 감내(Partition Tolerance)라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리다.
- 데이터 일관성 : 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
- 가용성 : 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 파티션 감내 : 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다는 것을 뜻한다.

- CP : 일관성과 파티션 감내를 지원하는 저장소. 가용성을 희생한다.
- AP : 가용성과 파티션 감내를 지원하는 저장소
- CA : 일관성과 가용성을 지원하는 저장소. 통상 내트워크 장애는 피할 수 없는 일로 여겨지므로, 분산 시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다. 그러므로 실세계에 CA 시스템은 존재하지 않는다.
예시
분산 시스템은 파티션 문제를 피할 수 없다. 그리고 파티션 문제가 발생하면 우리는 일관성과 가용성 사이에서 하나를 선택해야 한다.

위 그림은 n3에 장애가 발생해 n1, n2와의 통신이 불가능한 상황이다. n1, n2에 기록한 데이터는 n3로 전달되지 않고, 반대의 경우도 동일하다.
이 때, 가용성 대신 일관성을 선택한다면(CP 시스템), 세 서버 사이에 생길 수 있는 데이터 불일치 문제를 피하기 위해 n1, n2에 대한 쓰기 연산을 중단시킨다.
반대로 일관성 대신 가용성을 선택한다면(AP 시스템), 이전 버전 데이터를 반환할 위험이 있더라도 계속 읽기 연산을 허용하며 n1, n2에 쓰기 연산을 허용할 것이다. 그리고 파티션 문제가 해결된 뒤 새 데이터를 n3에 전송할 것이다.
CAP 정리의 문제
- Consistency와 Availability는 분산 시스템의 특성이지만 Partition Tolerance는 분산 시스템이 돌아가는 네트워크에 대한 특성이며, 이것은 엄밀히 따지면 이 정리의 대상이라고 할 수 없다.
- Partition Tolerance를 포기하고 CA를 선택할 수 있을것 같지만, 실제로는 절대 불가능하다.
- Consistency와 Availability가 네트워크 장애 상황일 때만 대칭성이 있고 정상일 때는 그렇지 않다.
PACELC
CAP 정리의 문제에 대해 Daniel Abadi가 제시한 정리다.
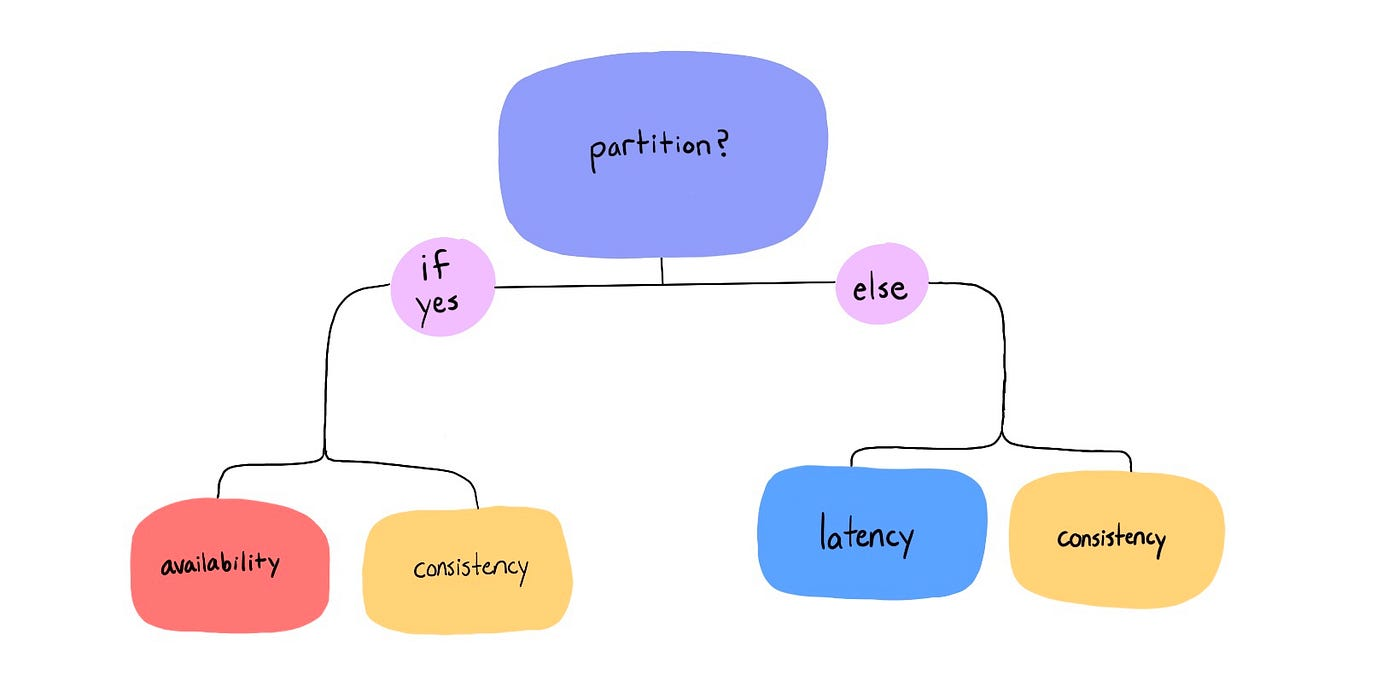
CAP 정리의 Consistency, Availability를 한 축으로 두고, 정상 상황이라는 새로운 축을 더한다.
분산 시스템은 Partition Tolerance 상황에서 Consistency, Availability 둘 중 하나를 선택해야 하는 것은 CAP 정리와 동일하고, 그외 정상적인 상황에서는 Latency와 Consistency 중 하나를 선택한다는 것이다.
다시 말해, Partition이 발생해 몇 개의 노드와 통신이 불가능할 때, 일관성 유지(C)를 위해 데이터 반영을 포기하던지 가용성(A)을 위해 통신 가능한 노드에만 데이터를 반영하던지 선택해야한다.
정상 상황일 경우에는 낮은 지연 시간(L)을 위해 일부 노드에만 데이터를 반영하던지, 일관성 유지(C)를 위해 모든 노드에 데이터를 반영하고 상대적으로 긴 응답시간을 가져갈지 선택해야한다.
시스템 컴포넌트
데이터 파티션
- 데이터를 여러 서버에 고르게 분산할 수 있는가
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화할 수 있는가
안정 해시를 사용해 데이터를 파티셔닝하면 아래와 같은 장점이 있다.
- 규모 확장 자동화 : 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되도록 만들 수 있다.
- 다양성 : 각 서버의 용량에 맞게 가상 노드의 수를 조정할 수 있다. 고성능 서버는 더 많은 가상 노드를 갖도록 설정할 수 있다.
데이터 다중화
높은 가용성과 안정성을 확보하기 위해서는 데이터를 N개 서버에 비동기적으로 다중화(replication)할 필요가 있다.
이 때 서버를 선정하는 방법은 키를 해시 링 위에 배치해 시계 방향으로 순회하며 만나는 첫 N개 서버에 데이터 사본을 복사하는 것이다.
하지만 선택한 N개 노드가 대응될 실제 물리 서버 개수가 N보다 작아질 수 있어 노드 선택 시 같은 물리 서버를 선택하지 않도록 해야한다.
데이터 일관성
여러 노드에 다중화된 데이터는 적절히 동기화 되어야한다. 정족수 합의 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성을 보장할 수 있다.
- N : 사본 개수
- W : 쓰기 연산에 대한 정족수. 쓰기 연산이 성공한 것으로 간주되려면 적어도 W개의 서버로부터 쓰기 연산이 성공했다는 응답을 받아야한다.
- R : 읽기 연산에 대한 정족수. 읽기 연산이 성공한 것으로 간주되려면 적어도 R개의 서버로부터 응답을 받아야한다.
W = 1 혹은 R = 1 인 구성의 경우 중재가는 한 대 서버로부터의 응답만 받음면 되니 응답속도는 빠를 것이다.
W + R > N 인 경우에는 강한 일관성이 보장된다. 일관성을 보증할 최신 데이터를 가진 노드가 최소 하나는 겹칠 것이기 때문이다.
일관성 모델
일관성 모델은 키-값 저장소를 설계할 때 고려해야 할 중요한 요소다.
- 강한 일관성(Strong Consistency) : 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다. 클라이언트는 절대로 낡은 데이터를 보지 못한다.
- 약한 일관성(Weak Consistency) : 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있다.
- 최종 일관성(Eventual Consistency) : 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사본에 반영되는 모델.
- 이 모델을 따를 경우 연산이 병렬적으로 발생하면 시스템에 저장된 값의 일관성이 깨질 수 있는데, 이 문제는 클라이언트가 해결해야 한다. (버전 정보를 활용)
비 일관성 해소 기법 : 데이터 버저닝
데이터 버저닝은 데이터를 변경할 때마다 해당 데이터의 새로운 버전을 만드는 것을 의미한다. 따라서 각 버전의 데이터는 변경 불가능하다.
버저닝은 벡터 시계를 보편적으로 사용하나 아래와 같은 단점이 존재한다.
- 충돌 감지 및 해소 로직이 클라이언트에 들어가야 하므로 클라이언트 구현이 복잡해진다.
- [서버:버전]의 순서쌍 개수가 굉장히 빨리 늘어난다. 이 문제를 해결하려면 그 길이에 임계치를 설정하고 임계치 이상으로 길어지면 오래된 순서쌍을 벡터 시계에서 제거하도록 해야한다.
그러나 이렇게 하면 버전간 선후 관계가 정확하게 결정될 수 없기 때문에 충돌 해소 과정의 효율성이 낮아지게 된다.
하지만 아마존 다이나모 DB가 실제 서비스에서 그런 문제가 벌어지는 것을 발견한 적이 없다고하니 대부분의 기업에서는 적용해도 괜찮은 솔루션일것이다.
장애 감지
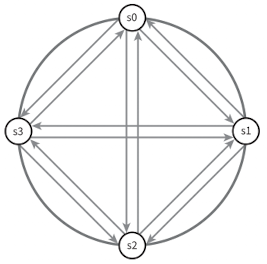
그림과 같이 모든 노드 사이 멀티캐스팅 채널을 구축하는 것이 가장 손쉬운 방법이나 서버가 많을때 비효율적이다.
가십 프로토콜(Gossip Protocol) 같은 분산형 장애 감지 솔루션을 선택하는 편이 보다 효율적이다.
가실 프롵토콜 동작 원리는 아래와 같다.
- 각 노드는 멤버십 목록을 유지한다. 멤버십 목록은 각 멤버 ID와 그 박동 카운터(heartbeat counter) 쌍의 목록이다.
- 각 노드는 주기적으로 자신의 박동 카운터를 증가시킨다.
- 각 노드는 무작위로 선정된 노드들에게 주지적으로 자기 박동 카운터 목록을 보낸다.
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신한다.
- 어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면 해당 멤버는 장애 상태인 것으로 간주한다.
일시적 장애 처리
장애를 감지한 시스템은 가용성을 보장하기 위해 필요한 조치를 해야한다.
엄격한 정족수 접근법을 쓴다면, 읽기와 쓰기 연산을 금지해야하며 느슨한 정족수 접근법을 쓴다면 이 조건을 완화해 가용성을 높인다.
영구 장애 처리
영구적인 노드의 장애 상태는 반-앤트로피(Anti-entropy) 프로토콜을 구현해 사본을 동기화하는 식으로 해결한다.
반-엔트로피 프로토콜은 사본들을 비교하여 최신 버전으로 갱신하는 과정을 포함하며, 사본 간의 일관성이 망가진 상태를 탐지하고 전송 데이터의 양을 줄이기 위해 머클(Merkle) 트리를 사용한다.
1. 키 공간을 버킷으로 나눈다.

2. 버킷에 포함된 각각의 키에 균등 분포 해시(uniform hash) 함수를 적용해 해시 값을 계산한다.

3. 버킷별로 해시값을 계산한 후, 해당 해시 값을 레이블로 갖는 노드를 만든다.

4. 자식 노드의 레이블로부터 새로운 해시 값을 계산하여, 이진 트리를 상향식으로 구성해 나간다.

5. 루트 노드의 해시 값이 일치하면 두 서버는 같은 데이터를 갖는 것이다. 그 값이 다른 경우 왼쪽 자식 노드의 해시 값을 비교하교, 그 다음 오른쪽 자식 노드의 해시 값을 비교한다.